HAI-Lab Events
第61回 関西合同音声ゼミ
The 61st Kansai Joint Speech Seminar
開催案内・Event-Info
| 日付・Date: | 2025年6月28日 (土) June 28, 2025 (Sat) |
| 時刻・Time: | 13:00 - 19:00 |
| 場所・Place: | 奈良先端科学技術大学院大学 ミレニアムホール NAIST Millenium Hall |
| アクセス・Access: | 奈良先端大へのアクセスについては下記をご覧ください. バスの経路と利用は少々繁雑ですのでご注意ください. Please see below for information on how to get to Nara Institute of Science and Technology. Please note that bus routes and usage are somewhat complicated. 奈良先端大へのアクセス and キャンパスマップ バススケジュール Access map and campus map Bus schedule 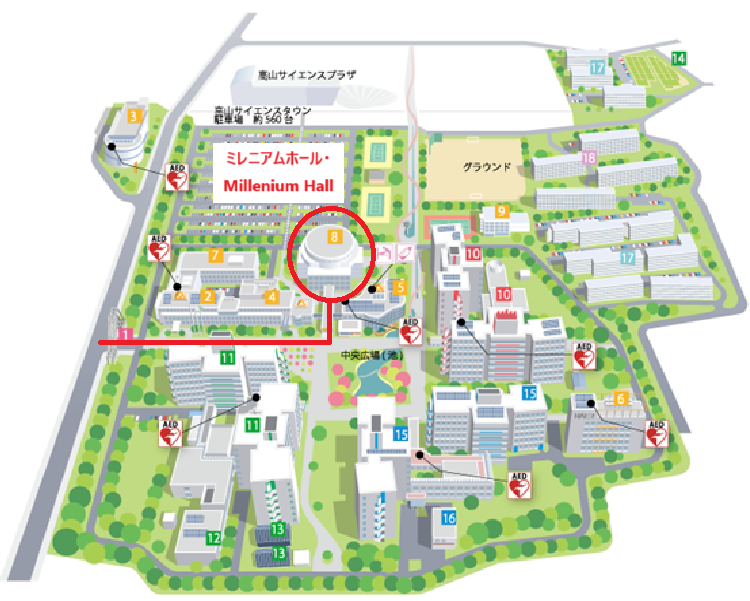 |
スケジュール・Schedule
| 12:30 – 13:00 | 受付 ・ Registration
|
||||||
| 13:00 – 13:40 | 招待講演 ・ Invited lecture
|
||||||
| 14:00 – 16:45 | ポスターセッション ・ Poster Sessions
|
||||||
デモ発表 ・ Demo Presentations
|
|||||||
| 17:30 – 19:00 | 懇親会 ・ Social Gathering
|
ポスター発表プログラム・Program
14:00 - 14:45 : 第1セッション ・ Session 1
| 番号 No. |
タイトル Title |
発表者名 Presenter |
大学名 University |
研究室名 Laboratory |
|---|---|---|---|---|
| 1 |
Hybrid H3-Conformerによる頑健な長時間音声認識
発表概要・Abstract
近年、多くの音声認識タスクにおいてConformerは非常に高い性能を達成している。一方で、Conformerのような自己注意機構をもつモデルは、長文音声に対しては処理に非常に時間がかかるだけでなく、性能も低下することが知られている。この問題を解決するため、本研究では、自己注意機構の代替として構造化状態空間モデルの一種であるHungry Hungry Hippos (H3) を導入することを提案する。線形オーダーの計算量で長文シーケンスを効果的にモデル化することができるというH3の特長を活用することによって、我々の提案するH3-Conformerモデルは、長文音声の効率的かつ堅牢な認識を実現した。さらに、H3と自己注意機構を組み合わせたハイブリッドモデルを提案し、H3を上位層で、自己注意機構を下位層で使用することで、オンライン音声認識タスクの性能を大幅に向上させることを示した。 |
本多 智揮 | 京都大 | 河原研 |
| 2 |
Multi-lingual and Zero-Shot Speech Recognition by Incorporating Classification of Language-Independent Articulatory Features
発表概要・Abstract
We address multi-lingual speech recognition including unknown or zero-shot languages based on the International Phonetic Alphabet (IPA) and articulatory features. Articulatory features are language-independent representations for IPA based on phonetic knowledge. In the previous studies, however, they were mostly limited to two dimensions of place of articulation and manner of articulation. Moreover, the classification of articulatory features were not well aligned with phone recognition. In this study, we adopt a comprehensive 24-dimensional vector representation, and propose a training method in which IPA tokens and their corresponding articulatory features are simultaneously predicted based on CTC alignment. Experiments are conducted by fine-tuning the wav2vec 2.0 XLS-R model over 22 languages, and the results demonstrated significant improvements on average as well as in zero-shot language settings. |
馬越 亮 | 京都大 | 河原研 |
| 3 |
温州語音声から中国標準語テキストへの変換
発表概要・Abstract
温州語は中国標準語と大きく異なる方言であり,最も複雑な中国方言の一つとされている.中国北部などの人々には理解されにくく,深刻なコミュニーケーション障壁となっている.そのため,温州語と中国標準語間の変換は円滑な意思疎通のために不可欠である.しかし,温州語は低リソース言語であり,公開されているデータセットが存在しない.そこで本研究では,温州語音声と対応する中国標準語テキストの並列データセットを作成し,温州語音声から中国標準語テキストへの変換のベンチマークモデルを構築した. |
高志鵬 | 同志社大 | 加藤研 |
| 4 |
口唇口蓋裂音声認識の性能向上に向けた効率的な学習データ収集方法の提案
発表概要・Abstract
本研究では,口唇口蓋裂者(CLP)の音声を認識する音声認識システムを提案する.口唇口蓋裂者の発話特徴は健常者のものと異なるため,口唇口蓋裂者の音声認識の正解率は,健常者のものよりも低い.また,口唇口蓋裂者は発話に負担があるため,音声認識モデルを学習するための十分な量の音声を収録できないという課題がある.そのため,私たちは口唇口蓋裂者音声認識モデルの性能を向上させるための効率的な学習データ収集方法を提案する.私たちは口唇口蓋裂者の誤りやすい音素を多く含んだ音声を収集することが音声認識モデルの性能向上につながると仮定した.実験では,日本語口唇口蓋裂者1 名につき音声を収録しデータセットを作成した.データセットのうち少量を学習データとし,音声認識モデルを学習させた.認識結果の誤り数を音素ごとに計算し,誤り音素の分布と近い音素分布をもつ音声をデータセットから学習データに追加した.この作業を繰り返すことで,学習データを被験者の誤り傾向に適合することができる.実験の結果,提案手法はベースラインよりも有意的な性能向上が見られた. |
土師 梧刀 | 神戸大 | 滝口研 |
| 5 |
事前学習済み条件付きGANによる感情字幕生成と主観評価
発表概要・Abstract
本研究では,発話時の感情によってフォント特徴が変化する字幕生成を提案し,手法の有効性を主観評価実験によって検証した.提案手法は,感情の強度を条件とする条件付きGANを利用している.また学習において,感情ラベルを持たない大量のフォントデータを用いた事前学習を行うことで感情とフォント特徴間の関係性の学習を促進している.実験では,生成時に与えた感情強度と被験者が感じた強さの順位に整合性が見られた.今後は,本手法を発展させることで,音声入力から感情字幕をEnd-to-End で生成する統合的なモデルの実現が期待される. |
和田 航次郎 | 神戸大 | 滝口研 |
| 6 |
Music Structure Labeling via Joint Learning of Feature Extraction and Clustering
発表概要・Abstract
We present a method of music structure analysis that aims to partition a music recording into musically meaningful segments and group similar segments with the same label. We propose a jointly-trainable network that has a feature extraction subnetwork followed by segmentation and clustering branches. The extraction subnetwork is implemented with a Transformer encoder, whose multi- head self-attention mechanism is expected to learn multifaceted self-similarity matrices in a data-driven manner. The clustering branch is implemented by deep- unfolding the expectation-maximization (EM) algorithm of a Gaussian mixture model and thus has no trainable parameters. The segmentation branch is introduced for supervised boundary detection, encouraging the temporal continuity of labels estimated by the clustering branch. The evaluation results show the effectiveness of the joint optimization and the superiority of the proposed method over state-of-the-art methods. |
Tsung-Ping Chen | 京都大 | 吉井研 |
| 7 |
ロボットによる親密行動に対するユーザの許容予測
発表概要・Abstract
本研究は状況に応じた適切な行動選択を実現するために、エントレインメントを用いてユーザの認識するロボットとの親密さと親密行動の許容の予測を目指す。 著者らはロボットが親密行動を行うシナリオでの対話実験を実施し、親密行動の実施を判断する上で有用な変数が何かを調査した。対話中のエントレインメント指標と親密行動に関する主観評価との関係を分析した結果、特定のエントレインメント指標が親密行動の予測に寄与することが明らかになった。 |
小松 秀輔 | 奈良先端大 | 吉野研 |
| 8 |
Evaluating the contributions of auditory and tactile sensations in augmented sound-image perception using pre-virtual-leading hypersonic signals
発表概要・Abstract
This study proposes a method for augmenting sound-image perception using pre-virtual-leading hypersonic signals. In this method, the hypersonic signals are used to augment perception without affecting the content of main signals. Subjective evaluation experiments were conducted to confirm the perceptual pathway of the hypersonic signals. |
今中 崚太 | 立命館大 | 西浦研 |
| 9 |
Design of Pin-spot Audio Using Double Sideband with Suppression Carrier Modulation with Sideband Division for Speech Leakage Reduction
発表概要・Abstract
This study presents the design of pin-spot audio using double sideband modulation with suppression carrier modulation through the use of frequency-based sideband division. The method delivers speech to the target listener using parametric array loudspeakers while reducing speech leakage in surrounding areas. |
岩上 瑞希 | 立命館大 | 西浦研 |
| 10 |
Evaluation of depth-directional sound image localization for acoustic metadata design based on video in object-based audio
発表概要・Abstract
Object-based audio is one playback method for multichannel audio. This study proposes a method for constructing sound images in object-based audio based on object positions estimated from video. Subjective evaluation experiment confirmed the depth-directional sound image position that showed the highest consistency with the video. |
加藤 昴 | 立命館大 | 西浦研 |
| 11 |
Voice conversion-based data augmentation with noise style encoder for optical laser microphone
発表概要・Abstract
Optical laser microphones suffer from quality degradation due to high-frequency attenuation and additional noise. In speech enhancement tasks for them, a large amount of training data is required. This study proposes a voice conversion-based augmentation method that simulates degraded speech for model training by extracting noise characteristics from real recordings using a noise style encoder. |
中野 裕貴 | 立命館大 | 西浦研 |
| 12 |
GNNを用いた音源強調
発表概要・Abstract
本研究は,単一チャンネルの音声信号における雑音抑圧と残響除去を目的としています.CNN/RNNが苦手とするサンプル間の明示的な関係性学習を補完するため,グラフ構造で効率的に情報を処理できるGNNをUNet構造のボトルネック部分に3層組み込んだモデルを提案しました.入力は時間領域または周波数領域で処理され,グラフ構造はランダムと類似度の2種類を比較しました.実験では,雑音抑圧,残響除去,両方の組み合わせについてPESQ,STOI,SI-SDRを用いて評価しました.結果として,雑音抑圧では周波数領域のランダムグラフ,残響除去および両タスクでは時間領域のランダムグラフが最も良いSI-SDRを示し,GNNの有効性が確認されました. |
森川 泰輔 | 龍谷大 | 片岡研 |
| 13 |
加齢性難聴者の聞き取り補助に向けた声質変換の有効性検証
発表概要・Abstract
補聴器は音量の増幅やノイズ除去により,加齢性難聴者の聞こえを改善する.しかし,声質によっては補聴器による聞こえの改善が十分に見込めない.本研究では,声質変換を行うことによる聞こえの改善効果を検証する.まず,難聴者の聴覚特性の再現下で,音声認識モデルを用いて様々な話者の音声認識率を測定し,音声認識率が高い話者を見つける.次に,認識率が高かった話者を聞き取りやすい声質とし,声質変換モデルで学習する.最後に,学習した声質変換モデルを用いて認識率の改善を図る.結果から,声質変換によって聞こえが改善されることを示した. |
大谷 蒼太 | 大阪大 | 駒谷研 |
| 14 |
複数話者TTSの合成音声において参照話者の再現に関する検討
発表概要・Abstract
複数話者TTSにおいて、合成音声の話者の再現性の推定法を検討した。入力の参照音声から抽出したx-vectorと主観で定義した話者再現性のラベルを対にし、教師あり学習のロジスティック回帰モデルを用いた。入力特徴量の21条件を比較した結果、音声コーパス5種類(CSJ, JVS, JNAS, 方言, Xeno-canto)から抽出したx-vector(512次元)を用いたとき、正解率0.65を確認した。 |
張 珠煐 | 和歌山大 | 西村研 |
| 15 |
PixVoxLM: End-to-End Spoken Image Description via Vision Codec Language Models
発表概要・Abstract
Neural audio codecs can compress audio into compact, discrete units, enabling NLP models to tackle various speech-related tasks like text-to-speech (e.g., VALL-E, VALL-E X) and multimodal generation (e.g., LauraGPT, VioLA). While effective for sequential inputs, their use with visual data remains largely unexplored. In this work, we introduce PixVoxLM, an efficient framework that bridges vision-language models and neural audio codecs to solve the Image-to-Speech (I2S) task. Evaluated on the Flickr8k dataset, PixVoxLM outperforms existing I2S approaches. Uniquely, it also supports visual-guided speech completion, offering new possibilities for real-world applications like speech-driven instruction. |
Chung Q. Tran | 奈良先端大 | サクテイ研 |
| 16 |
事前学習済みモデルを用いた小規模学習データにおける楽曲補完
発表概要・Abstract
本研究では楽曲の未完成な部分を生成する楽曲補完の研究に取り組む.近年,深層学習に基づく手法により補完の精度は向上した.しかし,既に亡くなっている作曲家の楽曲やマイナーなジャンルの楽曲などの小規模データに対する楽曲補完は,依然として前後の旋律の特徴を考慮した補完が困難である.故に本研究では,大規模データによる事前学習済みモデルを活用し小規模学習データにおける補完性能劣化を抑制可能かについて検討した. |
苗村 公明 | 立命館大 | 高島研 |
15:00 - 15:45 : 第2セッション ・ Session 2
| 番号 No. |
タイトル Title |
発表者名 Presenter |
大学名 University |
研究室名 Laboratory |
|---|---|---|---|---|
| 1 |
日本語に対応した音楽理解言語モデルの構築
発表概要・Abstract
本研究では,日本語に対応した音楽理解言語モデルの構築を検討する.音楽理解言語モデルとは,楽曲とそれに対する質問を入力すると,適切な回答を生成するモデルである.現在のモデルは英語のみに対応しており,日本語での利用が困難である.そこで本研究では,「既存モデルの入出力部で翻訳処理を行う方法」と「言語モデル部分を日本語モデルに置き換える方法」の2手法を用いて日本語での回答生成を行い,その出力の比較評価を行った. |
原田 優稀 | 立命館大 | 高島研 |
| 2 |
多人数チャットコーパスにおける参加者間の関係性の推定
発表概要・Abstract
While most existing dialogue studies focus on dyadic (one-on-one) interactions, re- search on multi-party dialogues has gained increasing importance. One key challenge in multi-party dialogues is identifying and interpreting the relationships between participants. This study focuses on multi-party chat corpus and aims to estimate participant pairs with specific relationships, such as family and friends. The proposed model extracts features from the input text, including the number of utterances and the frequency of honorific expressions, and uses logistic regression model to estimate relationships. Experimentations demonstrated that the proposed system significantly outperforms ChatGPT in relationship estimation tasks. |
福重 茜 | 京都大 | 河原研 |
| 3 |
Could MM-LLMs understand sign language? A novel approach to SLR
発表概要・Abstract
While recent advances in Isolated Sign Language Recognition (SLR) have improved performance substantially, data scarcity and the sole reliance on glosses hinder further progress. This ongoing work proposes a new approach to SLR aimed at minimizing these limitations. By text matching between MM-LLM-generated action descriptions and Sign Language dictionary entries, we produce a novel semi-phonetic representation for signs, and are able to perform Isolated SLR on signed languages lacking training video data. Current experiments with off-the-shelf models on a custom-created dataset show weak improvements over a random baseline. Future work includes extensive prompt engineering, end-to-end fine-tuning, and data augmentation, and is expected to generate interesting insights into the capabilities of MM-LLMs in fine-grained Action Recognition and Sign Language Understanding. |
Santiago P. Gutierrez | 京都大 | 河原研 |
| 4 |
語用論理論はLLMの推意理解能力を強化する
発表概要・Abstract
The ability to accurately interpret implied meanings plays a crucial role in human communication and language use, and language models are also expected to possess this capability. This study demonstrates that providing language models with pragmatic theories as prompts is an effective in-context learning approach for tasks to understand implied meanings. Specifically, we propose an approach in which an overview of pragmatic theories, such as Gricean pragmatics and Relevance Theory is presented as a prompt to the language model, guiding it through a step-by-step reasoning process to derive a final interpretation. Experimental results showed that, compared to the baseline, which prompts intermediate reasoning without presenting pragmatic theories (0-shot Chain-of-Thought), our methods enabled language models to achieve up to 9.6% higher scores on pragmatic reasoning tasks. Furthermore, we show that even without explaining the details of pragmatic theories, merely mentioning their names in the prompt leads to a certain performance improvement (around 1-3%) in larger language models compared to the baseline. |
佐藤 拓真 | 奈良先端大 | 吉野研 |
| 5 |
音響ベクトル時系列の自己注意重み特徴量を用いた吃音検出モデルのゼロショット・クロスリンガル評価
発表概要・Abstract
吃音は,音素や単語の反復,音の延長,長いポーズ,フィラーの挿入など様々な非流暢性現象として現れる.従来の吃音検出手法であるTransformerやLLMを用いる手法は数十時間分の対象言語の吃音音声データを学習データとして必要とするため,吃音音声データの少ない言語には適用できない.本研究では,音響的特徴に大きく依存しない特徴量である自己注意重み特徴量に基づく吃音検出モデルのゼロショット・クロスリンガル性能を評価する. |
宮原 絃造 | 同志社大 | 加藤研 |
| 6 |
主観による適合率を尺度としたE2E型擬音語認識手法の性能比較
発表概要・Abstract
擬音語認識システムの性能向上を目的とし、(1) モデルの学習データに含むオノマトペの種類を減らすことで連続する環境音にリズム感が生じる (2) 無作為型のみを用いることで不連続な環境音に対する不自然な繰り返しの出力を抑制できる、という仮説を検証した。主観評価を通じて適合率を比較したところ、先行研究と比較して、不連続な環境音に対しては、適合率の向上を確認した。一方で、連続する環境音には低下が生じた。 |
森山 颯太 | 和歌山大 | 西村研 |
| 7 |
交換単位に心象ラベルが付与されたデータセットを用いた交換内部の心象推定
発表概要・Abstract
音声対話システムにおいて,ユーザーの心象を推定することは不可欠である.従来の推定モデルは,交換単位(システム発話とユーザー発話)でラベル付けされたデータセットに依存しており,交換終了後に心象(楽しんでいるかどうか)を推定する.この問題設定には,2つの重要な制約が存在する.1つは,交換終了まで心象が不明であることであり,もう1つは,交換全体を通して心象が変化しないと仮定している点である.そのため,交換内部の心象を推定することが求められる.本研究では,交換単位のラベルしか学習に利用できない場合でも,交換単位よりも細かい粒度で心象を推定する手法を提案する.本アプローチの根拠として,まずデータセットの一部を分析し,ユーザーの実際の感情がより細かい粒度でどのように変化するかを調査した.次に,クラスタの分布と心象の関係を学習するモデルを構築し,短い区間におけるクラスタの分布から心象を推定できるモデルを開発した.最後に,提案手法の有効性を検証するために評価実験を実施した. |
雪澤 大地 | 大阪大 | 駒谷研 |
| 8 |
Investigating Challenges Faced by Professional Interpreters in Japanese–English Simultaneous Translation
発表概要・Abstract
While most speech translation technologies aim to replicate and potentially replace human interpreters, our long-term goal is to build an intelligent system that augments their abilities, offering support when they face difficulty. As a first step, this paper examines the challenges faced by professional interpreters using subjective ratings and eye-tracking data (pupil diameter). We analyze how subtle changes in pupil size vary across interpreter expertise levels in response to stimuli. Specifically, we compare simultaneous interpretation in both directions—Japanese-to-English and English-to-Japanese—to assess how native fluency in the source or target language influences cognitive load. |
Xi Hang | 奈良先端大 | サクテイ研 |
| 9 |
Speech-to-Articulatory Animation with wav2vec 2.0 and rtMRI for Visual Pronunciation Learning
発表概要・Abstract
Most computer-assisted pronunciation training (CAPT) systems for L2 learners rely on detecting mispronunciations using predefined phonemes and assigning scores, but they often lack visual feedback or detailed correction—limiting their effectiveness. This paper introduces a step forward in CAPT: a system that provides visual articulatory feedback using real-time MRI (rtMRI) landmarks. A key challenge is the scarcity of paired speech and articulatory data, usually limited to a few speakers, which hinders generalization. To overcome this, we fine-tune wav2vec 2.0 embeddings to predict articulatory contours as xy coordinates from rtMRI data. Tested on the USC-TIMIT dataset, our system successfully reconstructs articulatory motion from speech, advancing visual-based pronunciation training. |
Mushaffa R. Ridha | 奈良先端大 | サクテイ研 |
| 10 |
拡散モデルを用いた集中治療期脳波のデータ拡張
発表概要・Abstract
意識障害を伴う集中治療期の患者では,脳がてんかん発作などの重大な障害を来すリスクを迅速に判断し,適切に対応することが求められる.そのために脳波の持続的モニタリングが行われるが,データ量が膨大であるため,医師のみで全てを判読するのは困難であり,自動分類の導入が期待されている.一方で,集中治療期の脳波データは症例に偏りがあり,少数クラスの分類精度が低下するという課題がある.そこで本研究では,分類が不確実なサンプルに対して拡散モデルを用いて類似波形を生成し,逐次的に学習に組み込む動的なデータ拡張手法を提案する.329名から収録された脳波データを用いた分類実験により,少数クラスのRecall向上を含む分類性能の改善を確認した.また,生成波形は条件波形の特徴を反映しており,拡散モデルによる脳波生成の有効性が示唆された. |
備後 拓真 | 神戸大 | 滝口研 |
| 11 |
想起音声分類のための電流源推定に基づく脳磁図データ拡張
発表概要・Abstract
本研究では,脳活動データからの想起音声の識別精度を向上させるため,電流源推定に基づく脳磁図データのデータ拡張手法を提案した.大規模なニューラルネットワークを十分に訓練するには大量のデータが必要となる.しかし,脳活動データは収集が困難である.解決策の1 つとしてデータ拡張を用いることが考えられるが,脳活動データに対する効果的なデータ拡張手法はタスクごとに異なる.脳活動データに対するデータ拡張では頭外のセンサで観測された信号に対して処理が行われるが,それらの信号源は脳内に位置する.このため,脳内の信号に対して直接処理を行うことでより効果的にデータ拡張を行える可能性がある.提案したデータ拡張手法では,観測された脳磁図信号から脳内の電流源の時系列信号を推定した.次に,推定された電流源の信号に対して信号処理を適用した.最後に処理後の電流源信号から脳磁図信号を再構成し,モデル訓練用のデータセットに追加した.提案したデータ拡張手法を適用することで分類精度の向上が確認され,想起音声の識別機の訓練に有用かつ多様なサンプルを増やすことができることを示唆した. |
能勢 幸樹 | 神戸大 | 滝口研 |
| 12 |
音源物体の3Dガウス群表現に基づく多チャネル音源分離
発表概要・Abstract
本発表では,分散型マイクアレイ・カメラを用いた室内環境の視聴覚環境理解を目的として,カメラ画像 から推定された音源オブジェクトの三次元形状を事前情報として用いることで,観測音響信号に対する音源分離精度を改善する方法について述べる.3DGS およびオブジェクトへのセグメンテーションが完了しているという前提のもと,一つの音源オブジェクトを表現する3D ガウス群が,音源信号を共有しつつも,音量(重み)のみが異なる別々の音源であるとみなす. 具体的には,音源オブジェクトに対応する空間共分散行列に対して,3D ガウスの位置から計算される理論的な空間共分散行列の重み付き和を中央値とする複素逆ウィシャート事前分布を仮定することで,安定したMNMF のパラメータ推定を行う.2 つの音源オブジェクト(人間の三次元データ)を室内に配置したシミュレーションデータを用いた実験により,提案法の有効性を検証した. |
浅野 陽生 | 京都大 | 吉井研 |
| 13 |
時変空間モデルを用いた多チャネル非負値行列因子分解に基づく複数移動音源分離・追跡
発表概要・Abstract
本発表では,室内環境に分散配置された複数のマイクアレイ(位置は既知を仮定)を用いた,複数移動音源の分離および軌跡推定手法について述べる.滑らかな音源軌跡を表現するマルコフモデルと,時変なSCMを表現する音源位置に基づく複素逆ウィシャート分布(音源位置から計算される理論的なSCMが中央値)を事前分布とした,多チャネル観測信号に対する階層的な生成モデルを定式化する.最大事後確率 (MAP) 基準のもとで,音源軌跡およびモデルパラメータを一挙に反復最適化し,最終的にウィナーフィルタを用いて音源信号を推定する.提案手法の動作を検証するため,シミュレーションデータを用いて,4台の4チャネルマイクアレイを用いて2個の静止または移動音源の分離・定位を行う実験を行い,事前分布の導入が推定精度の向上へ寄与することを確認した. |
二瓶 竜乃介 | 京都大 | 吉井研 |
| 14 |
Evaluation of Distance Localization of Virtual Sound Source Based on Arrays of Electro-Dynamic Loudspeaker and Parametric Array Loudspeaker
発表概要・Abstract
This study constructs virtual sound sources in both the front and rear areas of a loudspeaker array using arrays of electro-dynamic loudspeakers and parametric array loudspeakers. To improve the accuracy of distance perception in the front area, distance-based weighting is applied based on the direct-to-reverberant ratio. |
山﨑 拓海 | 立命館大 | 西浦研 |
| 15 |
Evaluation of Near-Field Virtual Sound Source Construction Based on Early Reflection Suppression Using Inverse Filtering with a Parametric Array Loudspeaker
発表概要・Abstract
This study proposes a method for constructing a near-field virtual sound source using parametric array loudspeakers and inverse filtering to suppress early reflections. Objective and subjective evaluations confirmed that the proposed method improves the direct-to-reverberant ratio and enables a sound image to be perceived closer to the listener without headphones. |
金綱 零 | 立命館大 | 西浦研 |
| 16 |
Evaluation of Direct-to-Reverberant Ratio Error between Real Sound Source and Virtual Sound Source Constructed Based on Direct-to-Reverberant Ratio Control Using a Line Array Loudspeaker Consisting of Parametric and Electrodynamic Loudspeakers
発表概要・Abstract
This study proposes a method for constructing a virtual sound source by controlling the outputs of an integrated line array loudspeaker composed of parametric array loudspeakers and electrodynamic loudspeakers. Objective evaluation experiment confirmed the construction positions that successfully simulated the direct-to-reverberant ratio of a real sound source. |
入口 巧海 | 立命館大 | 西浦研 |
16:00 - 16:45 : 第3セッション ・ Session 3
| 番号 No. |
タイトル Title |
発表者名 Presenter |
大学名 University |
研究室名 Laboratory |
|---|---|---|---|---|
| 1 |
Evaluation of Demodulated Sound Pressure in Pin-Spot Audio Using Multiple Carrier Waves with Reflected Signals
発表概要・Abstract
This study proposes a method to improve the demodulated sound pressure at the focal point of pin-spot audio designed using reflections by introducing additional carrier waves through multiple reflection paths. The method employs delay control to align the phases of the carrier waves at the focal point. As a result, the sound pressure of the carrier waves increases at the focal point, leading to improved demodulated sound pressure. |
壷井 立成 | 立命館大 | 西浦研 |
| 2 |
Enhancement of Speech Signal at Audio-spot Based on Auditory Masking Using Parametric Array Loudspeakers
発表概要・Abstract
This study proposes a method for forming an audio-spot with enhanced speech signal based on auditory masking. Two parametric array loudspeakers use mixed signals: one combines speech with a masker, the other with an anti-masker. The anti-masker cancels the masker only at the control point, suppressing auditory masking and enabling speech perception there. |
橋田 朋希 | 立命館大 | 西浦研 |
| 3 |
Listening Area Control Based on Intermodulation Masking Using Whitened Carrier Wave for Parametric Array Loudspeaker
発表概要・Abstract
This study proposes a method to control the listening area using intermodulation masking with two Parametric Array Loudspeakers (PALs). One PAL emits an amplitude-modulated target signal, and another emits a whitened carrier wave. This allows for masking the target signal only in a specific, overlapping area. The effectiveness of this method was confirmed through evaluation experiments. |
森山 慶一 | 立命館大 | 西浦研 |
| 4 |
Cascaded Three-Stage Single-Channel Speech Separation Following by Noise Suppression and High-Frequency Components Reconstruction for Optical Laser Microphone
発表概要・Abstract
This study proposes a method for separating mixed speech recorded with an optical laser microphone. To improve the quality of the separated speech, the proposed method employs a cascaded framework that performs noise suppression and high-frequency components reconstruction following the speech separation. Evaluation experiments confirmed the proposed method improves the quality of the separated speech. |
孫 胡傑 | 立命館大 | 西浦研 |
| 5 |
光レーザマイクロホンを用いたマルチチャネルANCシステムの複数実環境下における実機性能評価
発表概要・Abstract
因果律制約の緩和を目的に、光レーザマイクロホンを用いたフィードフォワードアクティブノイズコントロール (FFANC) システムが提案されているが、残響環境では残響音を取得できず、騒音低減性能が低下する。そこで、本研究では、残響音を考慮するために、気伝導マイクロホンを追加したマルチチャネルFFANCシステムを提案する。複数実環境での実機実験により、提案システムの騒音低減性能が最も高いことを確認した。 |
水谷 真絃 | 立命館大 | 西浦研 |
| 6 |
音楽分離のための音楽特徴量を用いたデータ拡張手法の提案
発表概要・Abstract
本研究は、音楽から個々の楽器音源に分離する「音楽分離」の精度向上を目的とし, データセット不足を補うため, 異なる音楽の楽器音源をランダムに抽出し、 組み合わせるデータ拡張を行います. しかし、 これだけでは音楽的文脈を無視した品質の低いデータが生成されてしまう問題があるため、真のデータセットと拡張したデータセットから9つの特徴量を抽出し、機械学習モデルの識別器(MLP)を用いて拡張した音楽が真の音楽の特徴にどれだけ近いかを評価し、スコアの高い高品質なデータのみを選んで音楽分離モデルに学習させる手法を提案しました、結果として、選ばれたデータに偏りが生じてしまい, 精度向上には至りませんでした. 今後は, データの多様性を確保する工夫を加えることで, 精度の改善を目指します. |
平原 裕雅 | 龍谷大 | 片岡研 |
| 7 |
A Multifaceted Multi-Agent Framework for Zero-Shot Emotion Analysis and Recognition of Symbolic Music
発表概要・Abstract
We present the first attempt at zero-shot music emotion recognition (MER) to map musical pieces, represented in symbolic formats (e.g., ABC notation), onto the valence-arousal space. Conventional MER approaches typically train an end-to-end deep neural network (DNN). However, the performance of such supervised methods is limited due to the multifaceted and ambiguous nature of music emotions, compounded by the scarcity of MER datasets. To address this, we leverage knowledge transfer from large language models (LLMs) pre-trained on vast text and symbolic data. We hypothesize that LLMs possess capabilities in low-level music description and high-level emotion reasoning (not necessarily in a musical context. Accordingly, we propose a multi-agent framework that performs zero-shot MER by associating objective musical attributes (harmony, melody, rhythm, and structure) with subjective attributes (valence and arousal). |
Jiahao Zhao | 京都大 | 吉井研 |
| 8 |
参画型コンピュータ支援言語学習システムを用いた構文訓練における修正フィードバックの効果検証
発表概要・Abstract
第二言語(L2)によるコミュニケーション能力の獲得には十分な訓練が必要であるが,教室形式では十分な時間を確保できない.その不足を補う手段として対話型コンピュータ支援言語学習(DB-CALL)が注目されている.教師による指導では,修正フィードバックが重要とされている.本研究では,二体のバーチャルエージェントと会話するCALLシステムにWhisper ASRとGPT-4oを用いて修正フィードバックを提示する仕組みを実装した.このシステムを用いて日本人大学生を対象に修正フィードバックの有無による学習効果と定着度を比較評価した. |
田中 龍弥 | 同志社大 | 加藤研 |
| 9 |
日本人小学生による英単語復唱・音読における母音挿入・母音置換の経時変化
発表概要・Abstract
2020年度より小学校の中学年で外国語活動,高学年で教科として英語の授業が始まった.当研究室では2023年度から2つの公立小学校で163名の児童を対象に,英語学習初期の発音獲得を定量的に調査している.4年生11月と5年生7月に復唱形式,5年生12月に音読形式で英語音声を収録した.本研究では,初回の復唱から日本語訛りの発音が確認されたため,母音挿入と強勢母音の置換に焦点を当て,数種類の母音挿入・置換パターンを強制アライナで自動検出し,検出率を測った. |
西岡 学人 | 同志社大 | 加藤研 |
| 10 |
対話型鑑賞法を用いた芸術共同鑑賞支援ロボットについて
発表概要・Abstract
本研究では、美的発達段階を考慮した芸術鑑賞支援を目的として、対話型鑑賞を用いた協調的ロボットシステムを開発し、研究環境における実験を通じてその有効性を検証した。主観評価の結果を元にロボット及び発達段階の利用が鑑賞体験に与える影響についても分析した。結果として、本システムは利用意図を有意に高め、身体性は好意性・知的さ・楽しさの知覚に対して有意な効果を示した。 |
岩田 実莉 | 神戸大 | 滝口研 |
| 11 |
ユーザ心象改善に向けたシステム発話の対話行為推移との関係分析
発表概要・Abstract
対話システムでは高いユーザ心象を得られるように発話を行うことが重要である.しかし,現状のシステム発話では心象が低下する場合がある.改善の方法として心象が低下した要因を求め,その出現を防ぐことを考える.本研究では,システム発話の対話行為推移とユーザ心象の関係を明らかにする.連続する発話において対話行為が推移したことによる心象変化値と推移後心象値を分析した.結果として心象はシステムが連続して質問を行うことで低下し,ユーザの発話に感想や共感を述べることで向上することがわかった. |
石田 晃大 | 大阪大 | 駒谷研 |
| 12 |
リアルタイム音声対話システムのための応答タイミングと短文応答の同時予測
発表概要・Abstract
対話における応答タイミングは発話者の意図を表現するための有用な手段である.この観点から応答タイミングを予測する手法の研究が進んでいる.他方で,このような手法を有効に活用するためには,音声合成などの生成モジュールの遅延を緩和する仕組みが必要となる.このような背景に基づき,応答タイミングと遅延緩和のための短文応答を同時予測するモデルを提案する.提案手法は応答すべきか否かを連続的に予測しながら,応答と判定した際に対照学習に基づくランキング付けにより適切な短文応答を選ぶ.二つのタスクでの客観評価を行い,応答タイミング,短文応答選択の両方で同条件の比較手法に対して優れた結果であることを確認した. |
大中 緋慧 | 奈良先端大 | 吉野研 |
| 13 |
アバター傾聴対話システムにおける多様な頷きのリアルタイム予測
発表概要・Abstract
人間どうしの対話において、頷き・視線・表情などの非言語情報は言語情報同様に重要な役割を担っており、音声対話システムにおいても、これらの非言語情報を適切に表出することが求められている。非言語情報の中でも、傾聴対話システムにおいて特に重要であると考えられる頷きに焦点を当て、これらのタイミングと種類をリアルタイムに予測するモデルを提案する。提案モデルは2名の対話者の音声を入力とする次発話者予測モデルであるVAP(Voice Activity Projection)モデルに基づいており、相槌予測とのマルチタスク学習や汎用的な対話データを用いた事前学習などを取り入れている。データセットとして、傾聴対話データに対して追加的に聞き手ジェスチャーを収録したのち、頷きを3種類に分類し、アノテーションを行ったものを使用した。実験では、多様な頷きを予測するタスクにおいて相槌予測とのマルチタスク学習の有効性が示された。また、提案モデルをアバター傾聴対話システムに組み込み、主観評価実験を行ったところ、反応の自然さなどの点で従来手法を上回ることが示された。 |
加藤 利梓 | 京都大 | 河原研 |
| 14 |
Long-Term Memory in Chatbots
発表概要・Abstract
In human-AI interactions, especially with chatbots, maintaining long-term conversational context is critical for a more personalized and coherent experience. However, not all dialogue history may be necessary or beneficial to retain. This research investigates whether full conversation histories are essential, revealing that approximately 60% of past interactions may be deemed unnecessary. We examine three primary memory techniques—Long-Context (full history), RAG (retrieval-augmented generation), and Fine-Tuning—and highlight inefficiencies in using the full dialogue history indiscriminately. To address this, we propose a method to evaluate the importance of individual utterances by training a RoBERTa model on annotated datasets (LUFY, Locomo, and RealTalk) containing human-bot and human-human conversations with QA. Our results suggest that intelligently filtering conversation history can maintain user satisfaction while improving system efficiency, offering a promising direction for the future of memory-aware conversational AI. |
住田 龍宇一 | 京都大 | 河原研 |
| 15 |
発話者の年齢を考慮する音声対話システムの検討
発表概要・Abstract
音声対話システムの最適な言葉遣いや振る舞いは、ユーザーによって異なる。本研究では、話者年齢推定を音声対話システムに組み込むことにより、ユーザーの年齢を考慮する音声対話システムの検討を行う。自己教師あり(SSL )モデルを利用した、話者年齢推定の精度改善にも取り組む。 |
八木 理一・ 周 王子茜 |
奈良先端大 | サクテイ研 |
| 16 |
話者年齢推定手法における半教師あり学習の検討
発表概要・Abstract
本研究では、話者年齢層推定手法における半教師あり学習を検討した。話者年齢層の推定には、先行研究で提案された特徴ベクトル抽出ネットワークとSGANの識別器から構成されるモデルを使用した。ラベルなしデータをそのままSGANに追加する方法と、ラベルなしデータに擬似ラベルを付与して追加する方法の2つを検証した結果、前者は先行研究手法と比較してAccuracyが0.005向上したのに対し、後者は0.024低下した。 |
平間 光 | 和歌山大 | 西村研 |
参加者内訳・Participants
| 大学 University |
研究室 Laboratory |
参加者人数 #Participants |
発表件数 #Presenters |
懇親会参加者 Soc.Attendies |
|---|---|---|---|---|
| 京都大学 | 河原研 | 24 | 6 | 24 |
| 京都大学 | 吉井研 | 13 | 4 | 12 |
| 神戸大学 | 滝口研 | 7 | 5 | 0 |
| 大阪工業大学 | 鈴木研 | 7 | 0 | 2 |
| 大阪産業大学 | 高橋研 | 8 | 0 | 0 |
| 大阪産業大学 | 岩居研 | 4 | 0 | 2 |
| 大阪大学 | 駒谷研 | 16 | 3 | 16 |
| 同志社大学 | 加藤研 | 10 | 4 | 7 |
| 奈良女子大学 | 須藤研 | 0 | 0 | 0 |
| 奈良先端科学技術大学院大学 | 吉野研 | 9 | 3 | 4 |
| 奈良先端科学技術大学院大学 | SAKTI研 | 26 | 4 | 26 |
| 立命館大学 | 西浦研 | 26 | 12 | 26 |
| 立命館大学 | 高島研 | 4 | 2 | 4 |
| 龍谷大学 | 片岡研 | 8 | 2 | 4 |
| 和歌山大学 | 西村研 | 4 | 3 | 4 |
| 滋賀大学 | 市川研 | 0 | 0 | 0 |
| 滋賀大学 | 南條研 | 1 | 0 | 1 |
| 合計・Total | 167 | 48 | 132 |